As of today there are over 5 million people using Zeplin, which means there are lots of teams relying on Zeplin as their source of truth for product designs. We’ve heard from some that they need to retain printed copies of their screens for compliance purposes or have a backup copy of the screen images for their entire workspace for various reasons. We’ll show you how that’s possible with Zeplin’s public API and Javascript SDK so your team can take advantage of this option, too!
Here are the steps we’ll be covering below:
- Project Setup
- Accessing the Zeplin API
- Getting the list of Projects in the Workspace
- Getting a list of screens for each project
- Download Screen Images
If you haven’t set up Zeplin’s Javascript SDK before, check out our previous blog post on getting started! And if you want to see these steps in action, check out full walkthrough of these steps in this video:
Project Setup
In addition to the Zeplin SDK, you’ll need to install a few extra packages:
You’ll need Axios for our HTTP request handler to access the Zeplin API. The Rate Limit for requests to the Zeplin API is 200 requests per minute per user, so if you’re working with a lot of screens to download, we’ll also use the axios-rate-limit library to help make sure we throttle the requests.
Downloading and writing so many files at a time can be taxing on your system, so similar to rate limiting, we’ll be using the p-limit library to limit the number of concurrent promises running at a time.
And lastly, we use dotenv to create an environment file that’s git-ignored to safely store our personal access token and any other environment variables for this app.
If you want to install all of those in one line, here you go!
$ npm install @zeplin/sdk axios axios-rate-limit p-limit dotenvIn your Node project index.js file you can import all the libraries we’ve just installed. There’s also the built-in “FS” module which is used for making any changes on your local file system, which is how we’ll handle creating any directories and files that we download.
import axios from 'axios';
import 'dotenv/config';
import fs from 'fs/promises';
import pLimit from 'p-limit';
import rateLimit from 'axios-rate-limit';
import { ZeplinApi, Configuration } from '@zeplin/sdk';You should create an environment file, .env, in your root directory and paste in your Personal Access Token and Workspace ID.
You can find your workspace from the address bar when visiting your workspace in Zeplin’s Web App:
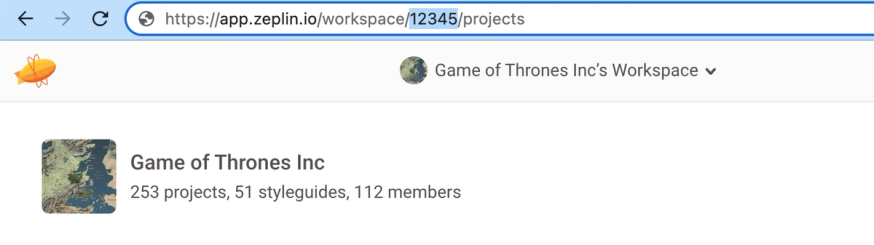
PERSONAL_ACCESS_TOKEN=ABCDE
WORKSPACE_ID=12345We can destructure them right here in your index.js file from process.env. We’ll also need to take note of the name of the output directory where we’ll store all of our screens in a variable called “dir” — I’ve called ours “Output”.
const { PERSONAL_ACCESS_TOKEN, WORKSPACE_ID } = process.env;
const dir = "Output"Accessing the Zeplin API
The process for downloading the screen images through the Zeplin API has 3 main steps.
- Get a list of project ID’s in your workspace from the getOrganizationProjects endpoint
- Using those project ID’s, retrieve screen data for all the screens in the project with the getProjectScreens endpoint.
- The response for the screen data will include a url, and we can access those URLs to download the image and create a file on your hard drive with the FS module.
For reference, you can check out the Zeplin API Docs for more information and a full list of endpoints available.
We’ll set up our HTTP handler first. Zeplin’s Javascript SDK already uses Axios to handle any requests, but accepts a custom handler as the third argument and we’re going to use axios-rate-limit for that.
We’ll call on the rateLimit function and pass in axios.create() to use axios as the handler, and then a set of options where we want to have the max number of requests be 200, and per 60000 milliseconds, which is 1 minute.
const http = rateLimit(axios.create(), { maxRequests: 200, perMilliseconds: 60000 });Now we just need to update the third argument of ZeplinApi to be http, our new rate-limited handler. The 2nd argument is for advanced scenarios using a different hostname for Zeplin’s API calls, but we’re just going to be use the default api.zeplin.dev so we can just leave this as undefined.
const zeplin = new ZeplinApi(
new Configuration({ accessToken: PERSONAL_ACCESS_TOKEN }),
undefined,
http
);Getting the list of Projects in the Workspace
Now let’s create an async function called getAllProjects. Inside this function we’ll use an array for the projects to live in that will be returned once we get all the data from Zeplin.
const getAllProjects = async () => {
const projects = [];
let data;
let i = 0;
do {
({ data } = await zeplin.organizations.getOrganizationProjects(WORKSPACE_ID, {
offset: i * 100,
limit: 100,
}));
projects.push(...data);
i += 1;
} while (data.length === 100);
return projects.filter((project) => project.status === 'active');
};
So data will be from await zeplin.organizations.getOrganizationProjects and pass in the workspace ID. We can add an additional parameter for the offset and limit, which I’ve set to only return 100 projects at a time. This will continue looping until we receive less than 100 projects, which indicates that that’s the end of our project list.
Before we return the list of projects, we can also filter for only “Active” projects in case you do not want to save screen images for archived projects as well.
Quick note:
I’ve used the terms “Organization” and “Workspace” so far and there’s a reason for that. In 2021, Zeplin added a new pricing option called the Team plan which has a workspace concept too, but at the time of this blog post, the API is using Organization naming convention so we will continue to refer to it that way, but if you’re on a Team plan you can still access the Organization endpoint.
Now we’re going to be writing a couple more functions, so let’s wrap this all up into a single function called main() that we can call when we run this script.
const main = async () => {
const projects = await getAllProjects();
console.log(`There are ${projects.length} projects`);
}We’ll console log the number of projects here, and then call the main() function.
await main();Let’s try it. I’ll just type in “node index” in our terminal and we should see that we have a few projects.
$ node index
Getting a list of screens for each project
Now we’ll need to get the screen data from those projects. Create a new function called getProjectScreens and pass in the project object that we’ve just received from our first API calls to Zeplin. Something to note about the screen model is that it does not include the name of the project, so we’ll hang onto the project name by creating a variable and adding it to the screen model. This will help later on when we save our screens in a specific directory that’s named the same as the project.
const getProjectScreens = async (project) => {
const { name: projectName, numberOfScreens } = project;
}We can destructure it from the project’s data, and to make sure we’re not confused with the screen’s name key, we’ll rename it to projectName.
With the numberOfScreens property, we can figure out the number of iterations we’ll need by using the keys() method on a new Array. We’ll use those iterations to determine how many batches of 100 screens to collect.
const iterations = [...Array(Math.ceil(numberOfScreens / 100)).keys()];And each of those batches returns an array of screens, so we just need to make sure we flatten the array before we can use that data in the next step. Here’s what we’ll have so far for this function:
const getProjectScreens = async (project) => {
const { name: projectName, numberOfScreens } = project;
const iterations = [...Array(Math.ceil(numberOfScreens / 100)).keys()];
const screens = (await Promise.all(iterations.map(async (i) => {
const { data } = await zeplin.screens.getProjectScreens(
project.id,
{ offset: i * 100, limit: 100 },
);
return data;
}))).flat();
};As I mentioned before with the screen model not having a reference to the project name, we’ll just map over these results before returning them and add the project name key to each screen object.
const getProjectScreens = async (project) => {
const { name: projectName, numberOfScreens } = project;
const iterations = [...Array(Math.ceil(numberOfScreens / 100)).keys()];
const screens = (await Promise.all(iterations.map(async (i) => {
const { data } = await zeplin.screens.getProjectScreens(
project.id,
{ offset: i * 100, limit: 100 },
);
return data;
}))).flat();
return screens.map((screen) => ({
projectName,
...screen,
}));
};Downloading Screen Images
At this point, we’ll have screen data with the url of the image and we can write our function for downloading that image, called downloadScreen.
We’ll pass in a single screen object here, and then destructure the screen name, project name, and the url for the image:
const downloadScreen = async (screen) => {
const { name, image: { originalUrl }, projectName } = screen;
}Now in this variable called data we’ll use axios to get the url, setting the responseType to “stream”
const { data } = await axios.get(originalUrl, { responseType: 'stream' });Next we’ll call on FS to make the directory with the project name, using the variable dir that we declared earlier as the directory called “Output.” You may want to git-ignore this folder to prevent the entire contents of that folder being committed.
We then call on fs.writeFile() to write the file to the output directory as PNG files, with the 2nd argument being the data we grabbed from the image url. Here’s the entire function:
const downloadScreen = async (screen) => {
const { name, image: { originalUrl }, projectName } = screen;
const { data } = await axios.get(originalUrl, { responseType: 'stream' });
await fs.mkdir(`${dir}/${projectName}`, { recursive: true });
await fs.writeFile(`${dir}/${projectName}/${name}.png`, data);
};Now we’re ready to put all these individual requests together with the p-limit library I mentioned earlier to help us manage the concurrent downloads.
Inside our main() function, we can call our getProjectScreens function from the list of project ID’s that were returned, flatten that list, and log it in the console:
const main = async () => {
const projects = await getAllProjects();
console.log(`There are ${projects.length} projects`);
const screens = (await Promise.all(projects.map(
async (project) => getProjectScreens(project),
))).flat();
console.log(`There are ${screens.length} screens`);
}Then we’ve got to use the fs module to create the directory that we called “Output”, and just for good measure we’ll make sure to remove the directory in case it already exists so this script can run fresh and you won’t have to worry about overwriting.
const main = async () => {
const projects = await getAllProjects();
console.log(`There are ${projects.length} projects`);
const screens = (await Promise.all(projects.map(
async (project) => getProjectScreens(project),
))).flat();
console.log(`There are ${screens.length} screens`);
await fs.rm(dir, { recursive: true, force: true });
await fs.mkdir(dir);
}Finally, we’ll create a variable called “limit” which will be an instance of pLimit, setting the number of concurrent downloads to 20 for now. You are welcome to experiment with increasing that number, though, if your machine can handle it. Then map over the screens and calling the downloadScreen() function, and pass in that limited promise array to Promise.all() The entire main() function should look like this now:
const main = async () => {
const projects = await getAllProjects();
console.log(`There are ${projects.length} projects`);
const screens = (await Promise.all(projects.map(
async (project) => getProjectScreens(project),
))).flat();
console.log(`There are ${screens.length} screens`);
await fs.rm(dir, { recursive: true, force: true });
await fs.mkdir(dir);
const limit = pLimit(20);
const downloadScreens = screens.map((screen) => limit(() => downloadScreen(screen)));
await Promise.all(downloadScreens);
}Let’s try running it in your Terminal again with:
$ node indexAnd there you go! Open the Output folder to see it populate with screens.
You can now download all of your workspace screen images whenever you need to!
Since this is a command line application without any front-end UI, it could be helpful to have an idea of how far our progress is in downloading everything. You can use a library called Progress to visually represent the progress in our command line. This is covered more in the corresponding video and you can also see how it's done from the source code and more helpful scripts that use Zeplin's Javascript SDK from the Zeplin Community GitHub Repo.
If you have any questions or want to share what you're building, come join the developer community on our Discord server!